DataStructure Objects
DataStructure
The simplnx DataStructure can be filled with various types of objects. Those are all listed below. In the DREAM3D-NX user interface, the DataStructure of any pipeline can be inspected via the “DataStructure” view, shown below outlined in a yellow box at the right side of the user interface.
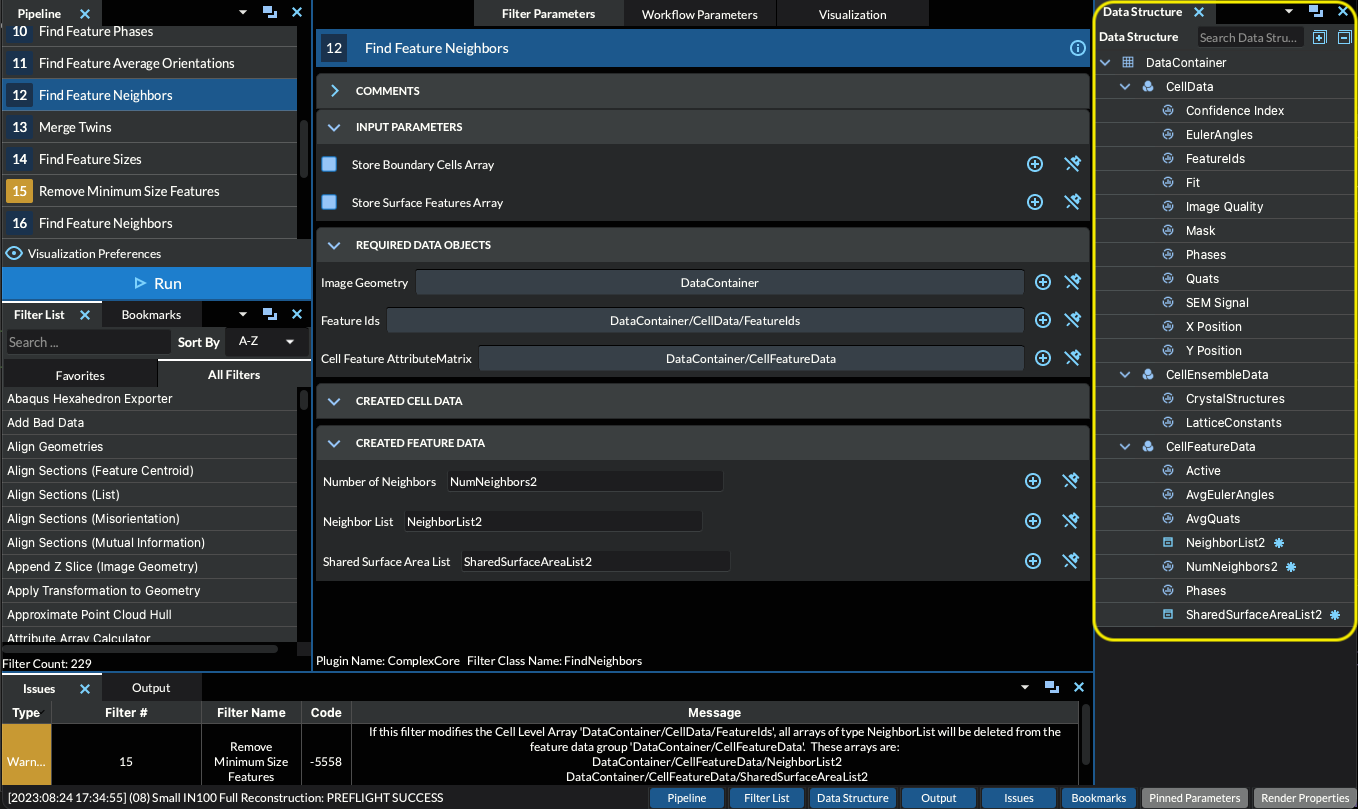
All DataObjects are stored in a DataStructure.
Multiple DataStructure objects are allowed in a python program.
- class DataStructure
- [data_path]
- [string]
Retrieves the DataObject at the given DataPath
- Parameters:
data_path (DataPath) – The DataPath (or string convertable to a DataPath) to retrieve.
- size()
- Returns:
An integer that is the total number of all objects that are held by the DataStructure.
- Return type:
int
- remove(data_path)
- remove(string)
- Parameters:
data_path (DataPath) – The DataPath (or string convertable to a DataPath) to remove from the DataStructure.
- Returns:
A boolean indicating if the path was removed or not.
- Return type:
Bool
- hierarchy_to_str()
- Returns:
A string that attempts to show the internal hierarchy of the DataStructure
- Return type:
string
- hierarchy_to_graphviz()
- Returns:
A string that attempts to show the internal hierarchy of the DataStructure formatted in the GraphViz ‘dot’ language.
- Return type:
string
- get_children(simplnx.DataPath)
- get_children(string)
# this is just sample code. The developer is expected to use these on well
# constructed DataStructure objects.
data_structure = nx.DataStructure()
num_objects = data_structure.size
did_remove = data_structure.remove(simplnx.DataPath("/Path/to/Object"))
hierarchy = data_structure.hierarchy_to_str()
hierarchy_gv = data_structure.hierarchy_to_graphviz()
top_level_child_paths = data_structure.get_children()
child_paths = data_structure.get_children(simplnx.DataPath("Group"))
child_paths = data_structure.get_children("/Path/to/Object")
DataObject
This is the abstract base class for all other objects that can be inserted into the DataStructure . It should never be used as the appropriate class from the list below should be used instead.
- class DataObject
- Variables:
id – Integer. The internal id value used in the DataStructure
name – String. The name of the object
type – simplnx.DataObject.DataObjectType value
The possible type values are:
simplnx.DataObject::Type::DataObject
simplnx.DataObject::Type::DynamicListArray
simplnx.DataObject::Type::ScalarData
simplnx.DataObject::Type::BaseGroup
simplnx.DataObject::Type::AttributeMatrix
simplnx.DataObject::Type::DataGroup
simplnx.DataObject::Type::IDataArray
simplnx.DataObject::Type::DataArray
simplnx.DataObject::Type::IGeometry
simplnx.DataObject::Type::IGridGeometry
simplnx.DataObject::Type::RectGridGeom
simplnx.DataObject::Type::ImageGeom
simplnx.DataObject::Type::INodeGeometry0D
simplnx.DataObject::Type::VertexGeom
simplnx.DataObject::Type::INodeGeometry1D
simplnx.DataObject::Type::EdgeGeom
simplnx.DataObject::Type::INodeGeometry2D
simplnx.DataObject::Type::QuadGeom
simplnx.DataObject::Type::TriangleGeom
simplnx.DataObject::Type::INodeGeometry3D
simplnx.DataObject::Type::HexahedralGeom
simplnx.DataObject::Type::TetrahedralGeom
simplnx.DataObject::Type::INeighborList
simplnx.DataObject::Type::NeighborList
simplnx.DataObject::Type::StringArray
simplnx.DataObject::Type::AbstractMontage
simplnx.DataObject::Type::GridMontage
simplnx.DataObject::Type::Unknown
simplnx.DataObject::Type::Any
data_object = data_structure["Image Geometry"] if data_object.type == nx.DataObject.DataObjectType.ImageGeom: print("Image Geometry") else: print("NOT Image Geometry")
DataPath
A DataPath is a simplnx class that describes the path to a DataObject within the DataStructure . The path is constructed as a python list of string objects or a “/” delimited string. DataPath also implements a few items from the ‘pathlib’ library.
DataPath can act as a List[str] object, such as getting the length or looping on the items.
data_path = nx.DataPath("root")
print(f'length: {len(data_path)}')
for item in data_path:
print(f' {item}')
- class DataPath
- (list_of_string)
- (delimited_string)
Constructs a DataPath object from either a List of strings or a ‘/’ delimited string.
- Parameters:
list_of_string (List[str]) – A list of strings
delimited_string (str) – A “/” delimited string (First introduced: v1.2.5)
array_path = nx.DataPath(['MyGroup', 'Euler Angles']) array_path = nx.DataPath("MyGroup/Euler Angles")
- [index]
Retrieves the Item at the given index. Zero based indexing. If index is out of range an exception will be thrown.
- Parameters:
index (int) – The element of the DataPath to retrieve.
- to_string(delimiter)
returns the DataPath as a delimited string.
- Parameters:
delimiter (str) – The delimiter to use
data_path = nx.DataPath("/root/foo/bar") print(f'{data_path.to_string("|")}') # [Output] root|foo|bar
- create_child_path(child_name)
Creates a new DataPath object that is the exisiting DataPath with the new child_path appended
- Parameters:
child_name (str) – This will be appended to the existing DataPath
- parts()
A tuple giving access to the path’s various components. Conforms to the pathlib specification. (First introduced: v1.2.5)
data_path = nx.DataPath("/root/foo/bar") path_parts = data_path.parts() print(f'path_parts: {path_parts}' ) # [Output] path_parts: ['root', 'foo', 'bar']
- parent()
The logical parent of the path. Conforms to the pathlib specification. (First introduced: v1.2.5)
data_path = nx.DataPath("/root/foo/bar") parent_path = data_path.parent() print(f'parent_path: {parent_path}' ) # [Output] parent_path: root/foo
- name()
A string representing the final path component. (First introduced: v1.2.5)
data_path = nx.DataPath("/root/foo/bar") last_path = data_path.name() print(f'last_path: {last_path}' ) # [Output] last_path: bar
- with_name()
Return a new DataPath with the name changed. If the original path is empty, then a DataPath with the name as the only part is returned. (First introduced: v1.2.5)
data_path = nx.DataPath("/root/foo/bar") name_change = data_path.with_name("NEW NAME") print(f'name_change: {name_change}' ) # [Output] name_change: name_change: root/foo/NEW NAME
DataGroup
The DataStructure is a flexible heirarchy that stores all simplnx DataObjects that are created. A basic DataObject that can be created is a DataGroup which is a simple grouping mechanism that can be thought of as similar in concept to a folder or directory that is created on the file system. The programmer can use the CreateDataGroupFilter filter to create any needed DataGroups.
result = nx.CreateDataGroupFilter.execute(data_structure=data_structure,
Data_Object_Path=nx.DataPath(['Group']))
DataArray
The DataArray is the main class that holds the raw data. It is typically a contiguous chunk of memory that is allocated to hold the data that will be processed. The DataArray has a few properties that should be well understood by the user before starting to develop codes that are based on the simplnx library.
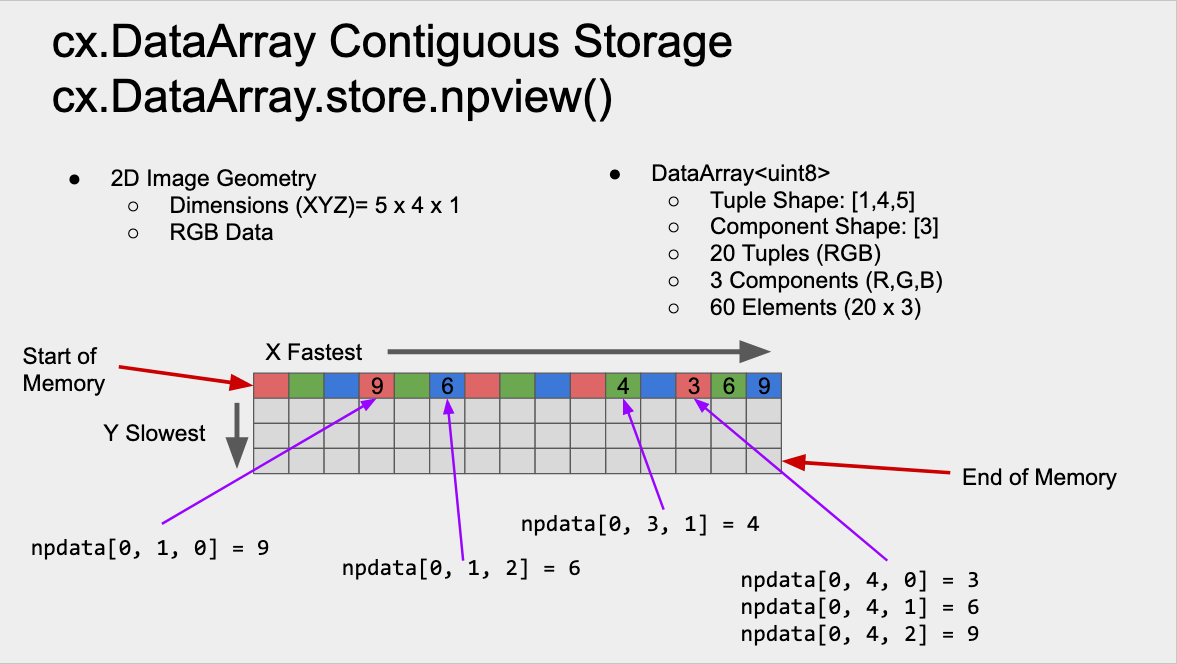
name: Each DataArray has a name that is assigned to it. Most any character can be used except for the ‘/’ character.
tuple_shape: The DataArray will have a tuple shape that is describe by an array values that are listed in “C” order of slowest to fastest moving dimension.
component_shape: At each tuple, there can be multiple values which are described by the component shape which is an array of values that are listed in teh “C” order of slowest to fastest moving dimension.
Referring to the figure above, The DataArray that has been created is a 2D DataArray with dimensions of 4 high and 5 tuples wide. Each tuple has 3 components, the RGB values of a color image. Refer to the memory schemtic in the above image to understand how this would be layed out in memory and subsequently accessed with the numpy API. The following is the python code that would craete the DataArray used in the example.
- class DataArray
- Variables:
name – The name of the DataArray
tuple_shape – The dimensions of the DataArray from slowest to fastest (C Ordering)
component_shape – The dimensions of the components of the DataArray from slowest to fastest (C Ordering)
store – The DataStore object.
dtype – The type of data stored in the DataArray
- resize_tuples()
Resize the DataStore with the given shape array.
- Variables:
shape – List: The new dimensions of the DataStore in the order from slowest to fastest
DataArray Example Usage
This code will create a DataArray called “2D Array” with tuple dimensions of [4,5], 3 components at each tuple, of type Float32 with every element initialized to “0.0” and then print the name, tuple_dimensions and component_dims of the created DatArray object
data_structure = nx.DataStructure() result = nx.CreateDataArrayFilter.execute(data_structure=data_structure, component_count=3, data_format="", initialization_value="0", numeric_type=nx.NumericType.float32, output_data_array=nx.DataPath(["2D Array"]), tuple_dimensions=[[4, 5]]) data_array = data_structure[output_array_path] print(f'name: {data_array.name}') print(f'tuple_shape: {data_array.tuple_shape}') print(f'component_shape: {data_array.component_shape}') print(f'dtype: {data_array.dtype}')
The output produced is:
name: 2D Array
tuple_shape: [4, 5]
component_shape: [3]
dtype: float32
DataStore
The DataStore is the C++ object that actually allocates the memory necessary to store data in simplnx/DREAM3D. The Python API is intentially limited to getting a Numpy.View() so that python developers can have a consistent well known interace to the DataArray. The programmer will never need to create from scratch a DataStore object. They should be fetched from a created DataArray by executing the Create Data Array filter.
- class DataStore
- Variables:
dtype – The type of Data stored in the DataStore
- length(data_store)
Get the number of tuples in the DataStore
- [index]
Get a value at a specified index. Use of the numpy view into the DataArray is preferred.
- resize_tuples()
Resize the DataStore with the given shape array.
- Variables:
shape – List: The new dimensions of the DataStore in the order from slowest to fastest
DataStore Example Usage
# First get the array from the DataStructure
data_array = data_structure[output_array_path]
# Get the underlying DataStore object
data_store = data_array.store
# Get the raw data as an Numpy View
npdata = data_store.npview()
# ------------
# The developer can also just inline the above lines into a single line
npdata = data_structure[output_array_path].store.npview
NeighborList
- class NeighborList[T]
- property tuple_shape: list[int]
The dimensions of the NeighborList from slowest to fastest (C Ordering)
- property component_shape: list[int]
The dimensions of the components of the NeighborList from slowest to fastest (C Ordering)
- property dtype: numpy.dtype
The type of the NeighborList elements
- get_list(grain_id: int) list[T]
Returns the target neighbor list.
- Parameters:
grain_id (int) – The grain id of the target list
- Returns:
The target list
- Return type:
list[T]
- set_list(grain_id: int, neighbor_list: list[T])
Set the target neighbor list to the given list.
- Parameters:
grain_id (int) – The grain id of the target list
neighbor_list (list[T]) – The replacement list
- get_value(grain_id: int, index: int) T
Returns the value at the given index in the target neighbor list.
- Parameters:
grain_id (int) – The grain id of the target list
index (int) – The index into the target list
- Returns:
The target value
- Return type:
T
- add_entry(grain_id: int, value: T)
Appends the given value to the target neighbor list.
- Parameters:
grain_id (int) – The grain id of the target list
value (T) – The value to append
- get_list_size(grain_id: int) int
Returns the size of the target neighbor list.
- Parameters:
grain_id (int) – The grain id of the target list
- Returns:
The target list size
- Return type:
int
- get_number_of_lists() int
Returns the total number of lists.
- Returns:
The total number of lists
- Return type:
int
AttributeMatrix
Attention
An AttributeMatrix is specialized DataGroup that has two main criteria that must be met when inserting into the AttributeMatrix:
The predominant use of an AttributeMatrix is to group together DataArray objects that represent DataArrays that all appear on a specific Geometry. For example if you have an Image Geometry that is 189 voxels wide (X) by 201 voxels tall (Y) by 117 voxels deep (Z), the AttributeMatrix that holds the various DataArrays will have the same dimensions, (but expressed in reverse order, slowest dimension to fastest changing dimension). This ensures that the arrays that represent that data are all fully allocated and accessible. This concept can be summarized in the figure below.

In the figure a 2D EBSD data set has been collected. The data set was collected on a regular grid (Image Geometry) and has 9 different DataArrays. So for each Scan Point the index of that scan point can be computed, this index value represents the tuple index into any given DataArray. That can be used to access a specific value of the DataArray that represents the value of the Array, Euler Angles for instance, at that tuple index. In the code below note how the dimensions are listed as slowest changing (Z) to fastest changing (X) order.
result = nx.CreateAttributeMatrixFilter.execute(data_structure=data_structure,
data_object_path=nx.DataPath(["New Attribute Matrix"]),
tuple_dimensions = [[117., 201., 189.]])
Geometry
Please see the Geometry documentation.
Pipeline
The Pipeline object holds a collections of filters. This collection can come from loading a .d3dpipeline file, or from programmatically appending filters into a nx.Pipeline object.
Attention
This API is still in development so expect some changes
- class Pipeline
This class holds a DREAM3D-NX pipeline which consists of a number of Filter instances.
- Variables:
dtype – The type of Data stored in the DataStore
- from_file(file_path)
- Variables:
file_path – PathLike: The filepath to the input pipeline file
- to_file(name, output_file_path)
- Variables:
name – str: The name of the pipeline. Can be different from the file name
output_file_path – PathLike: The filepath to the output pipeline file
- execute(data_structure)
- Variables:
data_structure – nx.DataStructure:
- Returns:
The result of executing the pipeline
- Return type:
- size()
- Returns:
The number of filters in the pipeline
- insert(index, filter, parameters)
Inserts a new filter at the index specified with the specified argument dictionary
- Variables:
index – The index to insert the filter at. (Zero based indexing)
filter – The filter to insert
parameters – Dictionary: The dictionary of arguments (parameters) that the filter will use when it is executed.
- append(filter, parameters)
- Variables:
filter – nx.IFilter: The filter to append to the pipeline
parameters – Dictionary: The dictionary of arguments (parameters) that the filter will use when it is executed.
- clear()
Removes all filters from the pipeline
- remove(index)
Removes a filter at the given index (Zero based indexing)
# Shows modifying a pipeline that is read in from disk # Create the DataStructure instance data_structure = nx.DataStructure() # Read the pipeline file pipeline = nx.Pipeline().from_file( 'Pipelines/lesson_2.d3dpipeline') create_data_array_args:dict = { "data_format": "", "component_count":1, "initialization_value":"0", "numeric_type":nx.NumericType.int8, "output_data_array":nx.DataPath("Geometry/Cell Data/data"), "advanced_options": False, "tuple_dimensions": [[10,20,30]] } pipeline[1].set_args(create_data_array_args) # Execute the modified pipeline result = pipeline.execute(data_structure) nxutility.check_pipeline_result(result=result) # Save the modified pipeline to a file. pipeline.to_file( "Modified Pipeline", "Output/lesson_2b_modified_pipeline.d3dpipeline")
- class PipelineFilter
This class represents a filter in a Pipeline object. It can be modified in place with a new set of parameters and the pipeline run again.
- get_args()
Returns the dictionary of parameters for a filter
- Returns:
The parameter dictionary for the filter
- Return type:
Dictionary
- set_args(parameter_dictionary)
Sets the dictionary of parameters that a filter will use.
- Variables:
parameter_dictionary – Dictionary: The dictionary of parameter arguments for the filter.
- get_filter()
Returns the nx.IFilter object
""" This shows how to loop on a pipeline making changes each loop. Filter [0] is the ReadAngDataFilter which we will need to adjust the input file Filter [5] is the image writing filter where we need to adjust the output file """ for i in range(1, 6): # Create the DataStructure instance data_structure = nx.DataStructure() # Read the pipeline file pipeline = nx.Pipeline().from_file( 'Pipelines/lesson_2_ebsd.d3dpipeline') # Get the parameter dictionary for the first filter and # modify the input file. Then set the modified dictionary back into # the pipeine at the same location read_ang_parameters = pipeline[0].get_args() read_ang_parameters["input_file"] = f"Data/Small_IN100/Slice_{i}.ang" pipeline[0].set_args(read_ang_parameters) # Do the same modification here for the 5th filter in the pipeline write_image_parameters = pipeline[5].get_args() write_image_parameters["file_name"] = f"Output/Edax_IPF_Colors/Small_IN100_Slice_{i}.png" pipeline[5].set_args(write_image_parameters) # Execute the modified pipeline result = pipeline.execute(data_structure) nxutility.check_pipeline_result(result=result)